1 前言
2017年Google提出Transformer模型。过去了四年,想要入门Transformer原本是非常容易的,网上的资源一搜一大堆,但是大同小异,或者说没说到的地方都没说到,初学者看了之后除非悟性极好,否则还是不能理解(比如我)。所以我想尽量详细地叙述这个模型,综合网上各种贴子,可能你会有熟悉感。
修完大学公共数学基础三部曲即可。
2 总体概述
首先祭出这张最经典的论文图。
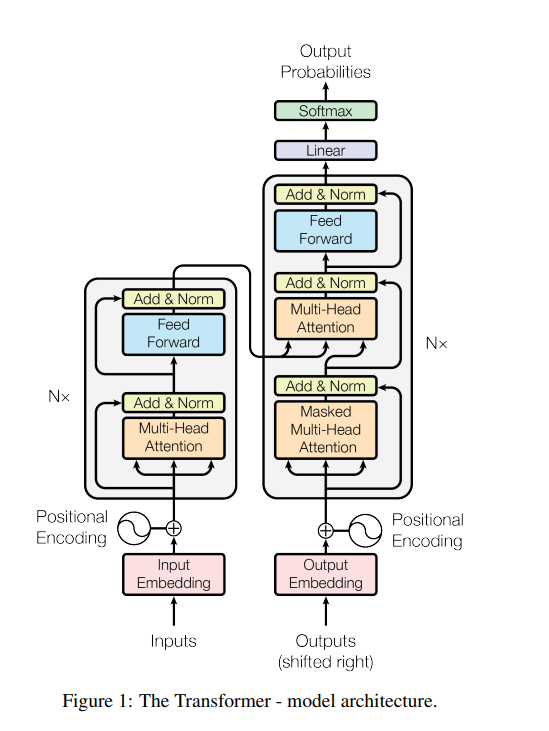
总体上Transformer模型使用的是 解码器-译码器 的模式,即encoder-decoder。直观上讲,
就是一个输入,被输入到encoder模块当中,encoder模块输出一个中间产物,中间产物被decoder使用(应该是反复使用),结合decoder本身的输入,经过一系列运算,输出结果(中间结果)。
理解上可以当做一个阅卷过程。encoder是试题组,综合考卷试题,给出一个给分细则,decoder像批卷老师,decoder输入是一份未批阅试卷,老师一手拿着给分细则打分,打分收到你之前题目作答情况,比如之前老师觉得给分太低,这时候有可能补偿式打分,最后将整分卷子批完。当然,给分一定合理吗?并不是。
这是个大概理解,接下来才是重点。
3. 各模块分析
Encoder
1. input embedding (输入嵌入)
以翻译为例。我要翻译一句话:I am a man.
我们中间是要对其进行数学运算,显然字符不合适,需要转化成数字。比如 数字1表示 I ,数字2表示 am,数字3表示 a , 数字4表示 man。只不过这是最朴素的想法,事实上一个句子中的每个单词,都有个词向量去表示,例如 man 可以表示成
这个叫做$one-hot$编码方式,最简单的一种,直接“看式思义“。但是这个词向量长度维数非常高(不应该叫”长度“, “大小”感觉还可以),存储开销比较大,于是利用某些技术,降低维度,
某些技术指词嵌入技术,比如$Word2Vec$, 可以在本站搜索,没搜索到应该是我还没写。 = =
转化成向量,很多计算就更加方便了,可以牵扯到矩阵的运算。向量->矩阵。
| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| I | $x_{(0,0)}$ | $x_{(0,1)}$ | $x_{(0,2)}$ | $x_{(0,3)}$ | $x_{(0,4)}$ |
| am | $x_{(1,0)}$ | $x_{(1,1)}$ | $x_{(1,2)}$ | $x_{(1,3)}$ | $x_{(1,4)}$ |
| a | $x_{(2,0)}$ | $x_{(2,1)}$ | $x_{(2,2)}$ | $x_{(2,3)}$ | $x_{(2,4)}$ |
| man | $x_{(3,0)}$ | $x_{(3,1)}$ | $x_{(3,2)}$ | $x_{(3,3)}$ | $x_{(3,4)}$ |
这样一个句子就转化成了矩阵,每一行是一个单词的词向量。实际上词向量列数有很多,整个矩阵大小是$sequenceLength\ ×\ d_{model}$ , 而真正的输入$X$,是很多个这样类似的矩阵,是一个 $batchSize\ ×\ sequenceLength\ ×\ d_{model}$ 的张量。
$d_{model}$ 论文中大小采用512。
$batchSize$ 一般指同时代入训练模型的实例个数。因为你总不能把所有句子所代表的矩阵全扔进去。
2. position embedding (位置嵌入)
位置信息在翻译当中是重要的。
You do like it. (你确实喜欢它) Do you like it? (你喜欢它吗?) 翻译上存在不同。
position embedding 就是刻画位置信息的编码,类似于词向量。
分为绝对位置编码,三角式,训练式,相对位置编码等等。建议阅读,
https://www.zhihu.com/search?type=content&q=transformer%E4%BD%8D%E7%BD%AE%E7%BC%96%E7%A0%81
论文当中采用三角式,
$PE(pos,2i) = sin(pos/10000^{2i/d_{model}})$
$PE(pos,2i+1) = cos(pos/10000^{2i/d_{model}})$
$pos$ 是单词在句子中的位置,$pos\in [0,sequenceLength)$ , $i \in [0,d_{model})$
而事实上,目前三角式用处比较小,相对位置编码更加重要,见
https://mp.weixin.qq.com/s/vXYJKF9AViKnd0tbuhMWgQ
最后信息添加的方式也非常简单,直接将输入矩阵$X = X+PE(X)$
3. Multi-Head Attention (多头注意力机制)
这是核心部分。
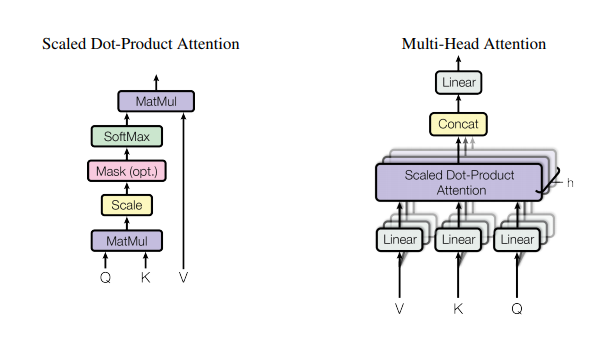
首先是$Q,K,V$。
我们在之前得到了处理过的$X$了,我们需要用$X$得到$Q,K,V$. 转化如下(图中三个Linear部分)
$W_i$ 一般情况下,最初可以是个$d_{model}×d_{model}$ 的随机矩阵,要“学习”的内容也正是它,因此他的初值可以是随机的。那为什么要转化成三个不同矩阵呢?原因是为了将输入矩阵映射到不同的子空间,增强了表达能力,提高了泛化能力。
下面我们先看不进行分头处理的注意力机制,就是解释下述公式。
我们先看 $QK^T$ 是什么。
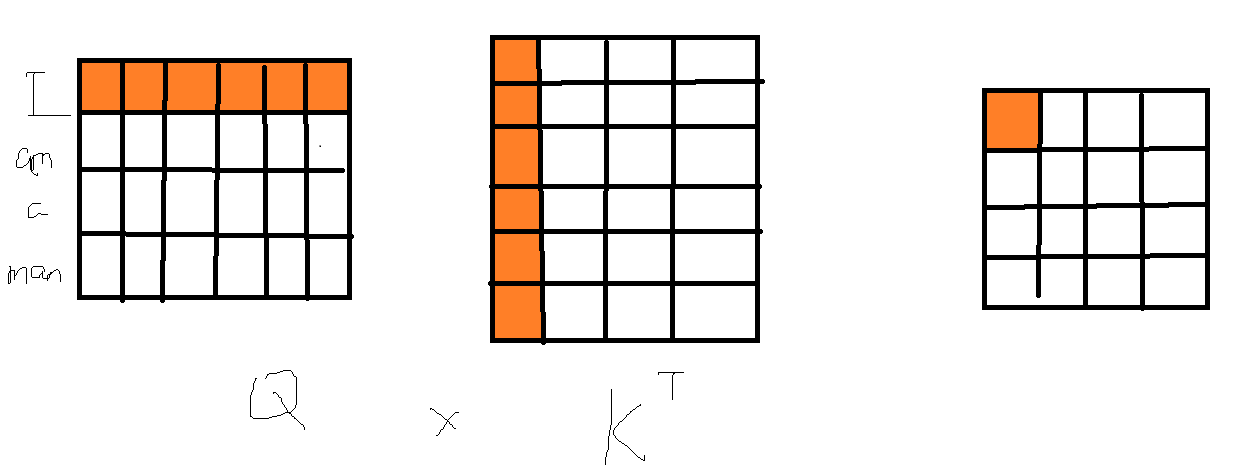
$QK^T$ 是一个 $d_{model}×d_{model}$ 的注意力矩阵,每一个元素 $(QK^T)_{ij}$ 表示第 $i$ 个词和第 $j$ 个词的相联程度,而这种相联程度使用对应词向量的点积进行描述。
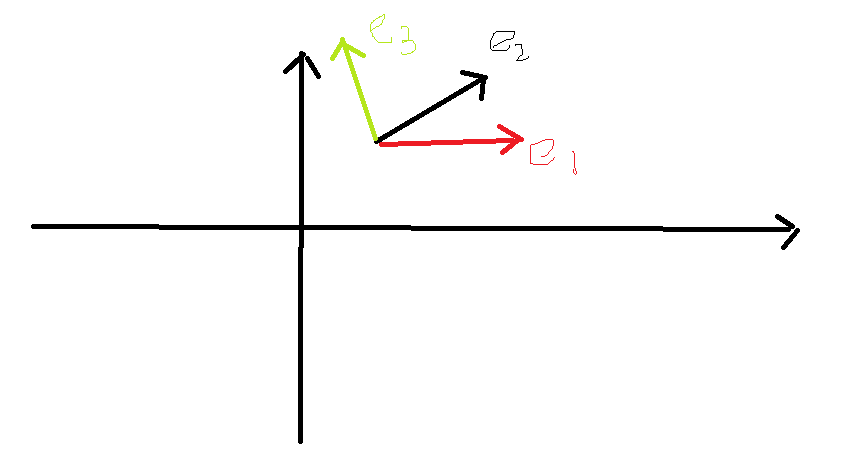
比如向量 $e_1,e_2$ 相似程度,我们可以用点积量描述,如图
$\vec{e_1}·\vec{e_2} = |\vec{e_1}||\vec{e_2}|cos<\vec{e_1},\vec{e_2}> = cos<\vec{e_1},\vec{e_2}>$
在向量运算当中, $e_1$ 比 $e_2$ 和 $e$ 的相似程度更高。
那么为什么要除以 $\sqrt{d_k}$ ?作用是把注意力矩阵变成标准正态分布,使得 $softmax$ 结果更加稳定。
那$softmax(x)$ 是个怎样的函数呢?
Softmax函数,或称归一化指数函数,是逻辑函数的一种推广。它能将一个含任意实数的K维向量
“压缩”到另一个K维实向量
中,使得每一个元素的范围都在
之间,并且所有元素的和为1。 ——百度百科
例如,$x = [1,2,3]$ , $softmax(x) = [0.09003,0.24473,0.66524]$
可以发现 $softmax$ 函数将向量元素之和归一化到1,并且“放大”了元素之间的差值。
不过存在的问题就是指数运算过后,可能有上溢/下溢,解决方法就是对其进行变式。
经过这一系列处理,得到一个注意力矩阵,可以看作一个评分机制,或者是权值矩阵。我们再乘以 $V$ ,本质上是对 $V$ 做一次求加权均值的过程。这样整个 $Attention(Q,K,V)$ 就获得了句子整体的信息。
最后我们来解释多头的含义。
所谓多头,就是指将矩阵均分成 $h$ 组,每一组分别做注意力计算,最后我们再将他们连接到一起,再做一个线性变换,得到注意力层输出。需要注意的是 $h$ 需要能整除 $d_{model}$ 。
(论文中 $h$ 取8)
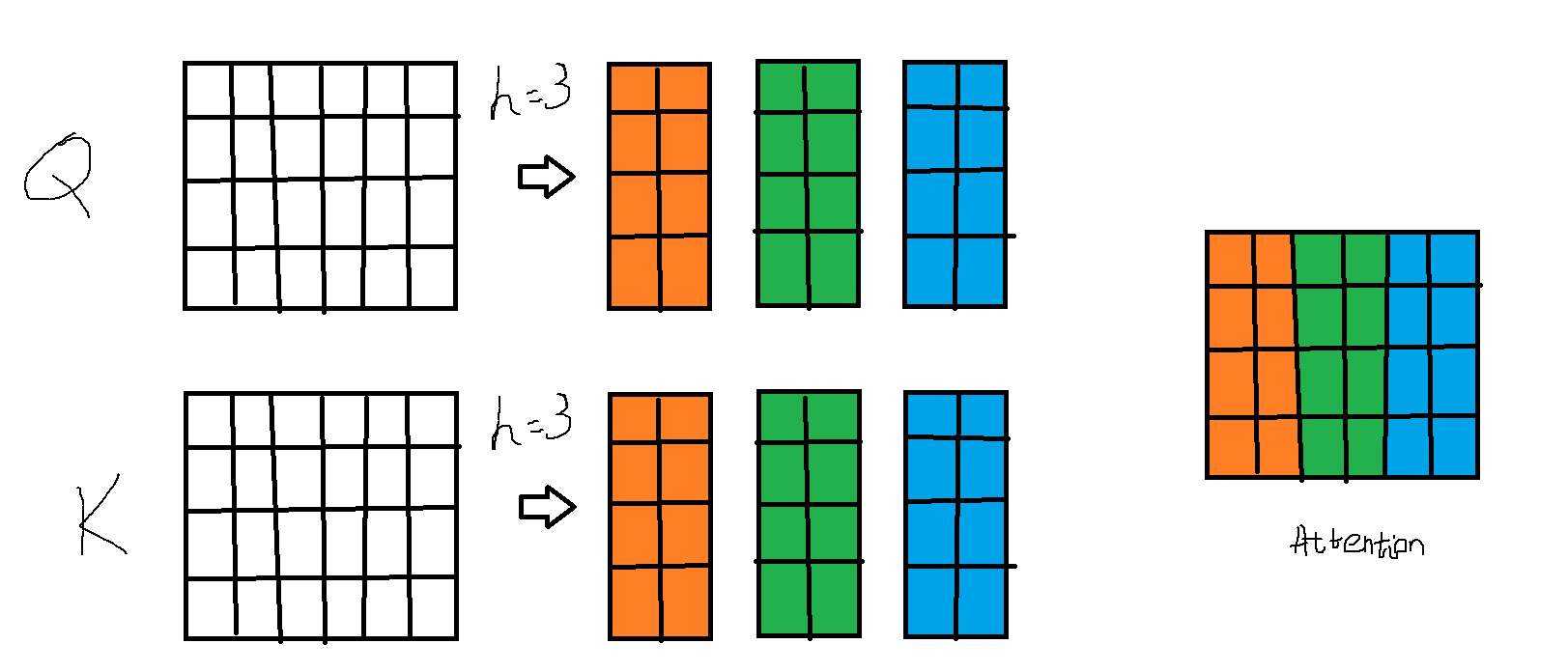
我们说注意力机制是一种词和词之间的关系,一个词在每个头更“关注”的部分不同,使用多个头可以反映这种不同的关注,接合起来使得矩阵蕴含更复杂的信息。
4. Add&Norm (残差连接与归一化)
$Add$ 过程是一个残差连接的过程,做的事情就是 $Output_{Attention} = Output_{Attention} + X$ 。这一处理主要目的是防止梯度消失。
$Norm$ 过程是一个归一化的过程,主要目的是将矩阵按行化为标准正态分布,加快收敛过程,加快训练速度。
5. Feed Forward (前馈神经网络)
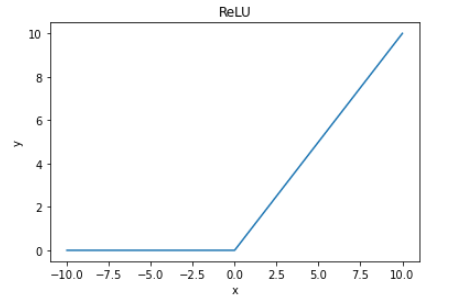
前馈神经网络主要作用是提供非线性转换,增强模型泛化能力。非线性部分指的是 $ReLu$ 函数,常见的一种激活函数。
Decoder
6. Outputs (解码器输入)
解码器也是有输入的,输入为译码器输入句子的译文。这种译文输入形式类似译码器输入,并不是“翻译”结果,这个 $Outputs$ 是我们给定的。但是我们并不能让模型以一个“上帝视角”去学习,如果整个译文信息在翻译时被全部观测到,那“学习”是效果差的。所以需要 $mask$ 技术使得翻译时不能够提前得到词的信息。
7. Masked Multi-Head Attention
$mask$ 分为两种。
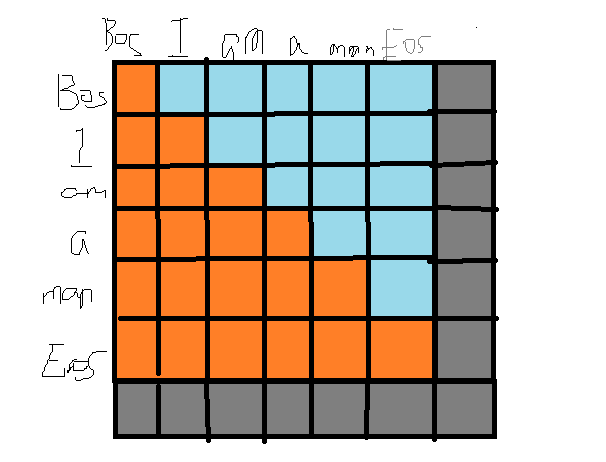
其中一种 $mask$ 是一种填充 ($padding$) 技术,因为句子长度不一,我们并行处理的张量规模需要一致,因此我们选择其中最长的句子长度作为句子的尺度,空出来的部分(灰色),使用 0 填充。
第二种 $mask$ 只在 $decoder$ 中使用,注意蓝色和橙色部分。我们不能利用未来的信息,所以也需要 $mask$ ,所利用的是之前的译文信息。使用 $-inf$ 填充。
8. Linear && Softmax
$Linear$ 负责将得到的解码器输出映射到一个高维向量,维度取决于词典大小。
$Softmax$ 负责将这个向量转化为一个类似概率的输出,这样我们把概率大的词作为翻译后的词汇。
3. 过程
例子 I am a man.
首先我们需要一个词典,记录用到的词。还有开始符(BOS),结束符(EOS),也被记录到词典里。
初始时,只有BOS一个符号。我们把句子以张量形式输入到译码器中,注意解码器和译码器并不是只有一个,而是有 $N$ 个复制。$Transformer$ 的特点之一就是方便并行处理,提高效率。通过编码器我们得到一个隐藏层 (中间矩阵),这时候我们利用这个编码器输出矩阵线性变换为解码器的 $K,V$ 输入,另外解码器还有输入部分就是给出的译文信息变换成的 $Q$ 。注意到编码器输出是要给到多个 $Decoder $ 的。每次翻译一个词,如下,
BOS -> BOS 我 -> BOS 我 是 -> BOS 我 是 一 …… -> BOS 我 是 一 个 男 人 EOS
我们定义损失函数,和真实翻译结果比较,运用反向传播算法,更新权值矩阵。
4. 结语
考虑初学理解有限,有不对的地方欢迎指正,也请详细说说,谢谢!
2021/9/1 BRB, a Observer